



Introduction
In Jmix, the JPA data model, hence database is a cornerstone of the application.
In the case of software development, the principle “if it works, don’t touch it” does not always work. Software changes are inevitable, database migrations too. And if database update goes wrong, you can lose data - one of the most valuable things for the business.
In our framework we use JPA over relational databases. Nowadays RDBMS are widely used in enterprise applications. Two key things that provide this success are: data consistency (it is very important in many business areas) and advanced ORM frameworks like Hibernate or EclipseLink that simplify application development.
Relational DB update is a complex process, we need to keep data consistent after migration is over and sometimes it is not as easy as it seems.
In the previous article we’ve made an overview of the database migration process in Jmix. In this article we’ll have a look at the DB migration challenges.
Migration Corner Cases
In the “Refactoring Databases: Evolutionary Database Design” book there are more than 20 cases for the database changes. Some of them can be quite dangerous and cause data loss.
Of course, you can easily identify refactoring actions that directly delete something. In Jmix we highlight changes that contain such operations as drop table or drop column with red colour in the DB migration scripts.
Let’s have a look at the database update cases that look safe but can cause issues during object model refactoring.
In Jmix, we use Liquibase for DB versioning, so we will use this tool as the reference further in the article.
Drop Table/Column
Even though this is a direct action that causes data loss, you can prevent harm by following the simple advice: “do not drop, rename”.
In the “Refactoring Databases: Evolutionary Database Design” book authors almost always use “Transition period” - time interval when DB objects still exist, but not used. It gives us some time to fix issues if something goes wrong with migration. For example, here is the "drop column" case representation:
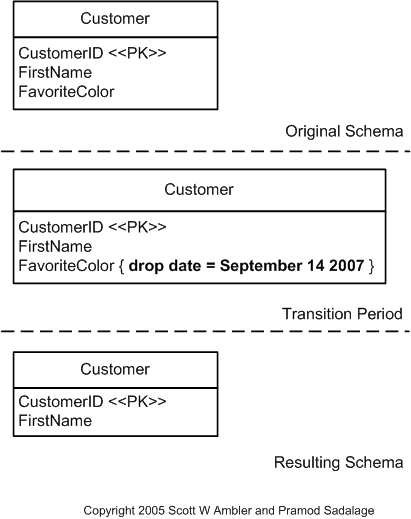
Rename Table
Class rename is a common operation, but in case of data model classes it usually causes DB table rename, especially if we haven’t specified the table name in the @Table annotation.
Liquibase will create the rename table statement for the operation. It is usually harmless, though it might lock the whole table. Be careful with it when applying the change on the prod server to avoid long downtime due to the table lock.
The potential issue when we renaming a table is not only DB lock, but SQL/JPQL queries specified in the app code in string format. We need to carefully review all such cases, because string references are harder to track than code ones, even with an IDE.
Such code review allows us to prevent the most unpleasant errors - runtime exceptions.
Rename Column
Renaming a class attribute is a simple refactoring operation if we use a modern IDE. This operation may cause a renaming operation for the corresponding DB column if we haven’t specified the column’s name explicitly.
As in the case of table rename, if we change a class attribute name, thus table column name, we need to review all related queries (SQL or JPQL) to be on the safe side.
For the attribute rename operation, the Liquibase tool will generate the “rename column” statement. Direct rename operation is supported by most databases (see Liquibase reference).
In Jmix we still generate “drop column + add column” Liquibase changeset. After it is generated, we need to update it by using the following sequence of operations:
- Add a temporary column
- Copy data from the column that should be renamed to the temporary one
- Drop column
- Create a new column with a new name
- Copy data from the temporary column to the new one
- Drop the temporary column
This will help us to avoid data loss on column rename.
Replace One-To-Many With Associative Tables
Let’s have a look at the example - we need to store information about cars and their owners. Here is the initial model:
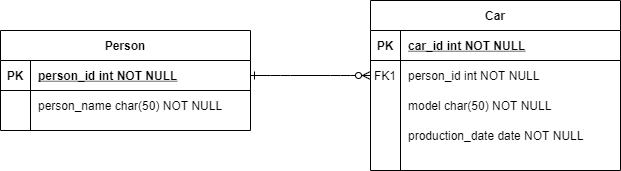
After some time we realised that we need to store the history of car ownership. When it comes to storing a history, it usually ends up with transforming an association cardinality. And our model transforms into this:
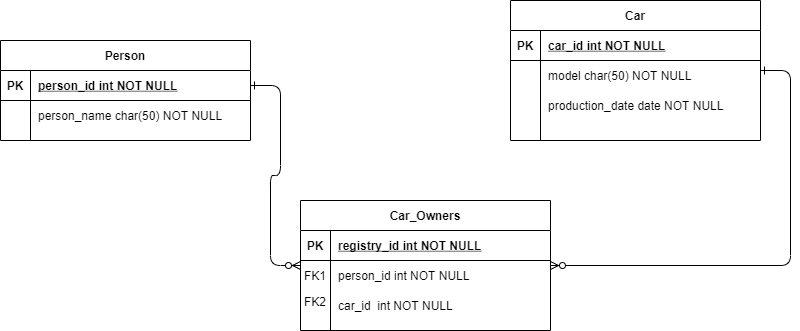
With Jmix Studio, changing cardinality is as simple as a couple of clicks in the entity editor. But on the DB level, changes are more serious. Jmix Studio generates the following change sets:
- Create association table
- Add two foreign keys to both entities
The Studio does not remove any foreign key columns from existing tables, we’ll need to do it manually. In our case, the column person_id will stay in the Car table.
But the more important thing is that Jmix does not migrate the existing information about links between entities. And if we need to keep this information, we need to migrate the data in the update scripts.
For the case of replacing many-to-one with associative table, the final changeset should contain the following steps:
- Create association table
- Add two foreign keys to both entities
- Insert data from both tables into associative table
- Drop redundant foreign key in one of the tables
This will allow you to keep history information about links between entities in the new table.
Change datatype
We usually do not change class attribute datatype often, in most cases we know the datatype at the business domain modelling stage. But sometimes we have to do it.
For example, we have a nice delivery tracking application developed for the US market. In the US, ZIP codes can be represented as nine digits (five+hyphen+four). The system works great and it was decided to start selling it for the UK customers. It turns out that in the UK ZIP code has a format like this: “SW1 4HY”. It means that we cannot store ZIP code as a number and should store it as a string.
Changing class attribute datatype is not a big deal, IDE and compiler will catch almost all issues at early stages. But for the database migration is usually a challenge.
In general, we cannot convert a datatype to any other datatype. In Jmix we generate two operators: “drop column” and “add column”. If you apply those directly, your data will be lost. To avoid this, follow the steps described in the “rename column” session.
Make Column Non Nullable
This change should not cause data loss, but may fail the whole DB update process if the column contains null values. In this case, we need to update the column and add default values.
Jmix generates only constraint creation Liquibase changeset. You need to change the generated script by specifying default value attribute defaultNullValue for null values in the column.
Another option - do not check the existing data by setting the validate attribute in the changeset. Before using this we should check if our particular RDBMS supports this feature. For more details can be found in the Liquibase documentation for this statement.
Add Unique Constraint
By adding constraints to a table (whether it is not null or unique key or something else) we introduce a potential failure for the database update process. The problem is that sometimes we just cannot check all possible data sets in all databases that will be updated by our changeset.
If we decide to add a unique constraint to a table, we can do it in the Jmix Studio by setting the corresponding attribute property or by creating a unique index in the visual editor.
Jmix will generate a base addUniqueConstraint Liquibase changeset. If we do not have information about the database that should be updated, we can add the validate attribute in the changeset.
For some RDBMSes, if we set validate to true, the unique constraint will be applied to newly created records only, the old data will not be validated. If we set it to false, the changeset will fail if there is non-unique data.
As an example, Oracle supports this mode (with some tricks though), but PostgreSQL doesn’t. We need to check the docs for our RDBMS to use this option.
If the DB does not support deferred constraint validation, we’ll have to update the data before applying the index.
First option - a manual process when we select all non-unique records and update them one-by-one. We’ll need to provide a clean migration instruction for our application that must be followed by DB admins.
If we want to automate the update a bit, we can assign a simple SQL update that will add a unique suffix to existing data in the column(s) that is going to be used in the unique constraint. This update can be added to the liquibase changeset. This option is simpler, but altering data may not be a great idea in some cases.
So, adding a unique constraint is a bit more complex than just issuing one ALTER TABLE statement, but it may be resolved with some additional actions stated above.
Conclusion
Database Migration is a complex process. Even with the modern tools and frameworks like Liquibase and Jmix you may bump into cases that may cause data loss or application runtime errors. Hope that this article will help you to avoid those pitfalls.





