



This article continues the BPMN: Beyond the Basics series – a look at the practical, less-discussed aspects of working with BPMN for developers. Today, we’ll talk about process variables: what they’re for, how they differ from programming variables, and how scope works. At first glance, it might seem like there’s nothing special about them, but if you dig below the surface, there’s more nuance than expected. In fact, we couldn’t fit it all into one piece article, so we’re splitting this topic into two parts.
Data in a Process
Process modeling traditionally begins with actions: approve a document, submit a request, sign a contract, plant a tree, deliver a pizza. Data is often left in the background, as if the performer intuitively knows where to get the right document or which pizza to deliver.
That works in human-centered, descriptive processes. People are expected to understand context, navigate loosely defined inputs, and follow general instructions. That’s why process models often resemble enhanced job descriptions more than software logic.
But when we move into automation, especially full automation, the game changes. A process without people must be explicit about how it handles data. It becomes not just a chain of steps, but a data processing mechanism. And if you want that mechanism to run fast and reliably, you need to understand how data is passed in, stored, transformed, and retrieved.
In short, a business process without data is like a horse without a cart — it might go somewhere, but it’s not carrying any value.
Data-Centric Processes and BPM Engines
Even though classic processes like document flow and multi-step approvals are still important for many companies, the shift toward full automation is well underway. Gartner predicted that by 2025, 70% of organizations will have adopted structured automation—up from just 20% in 2021. And the whole workflow automation market? According to Stratis Research report, the workflow automation market is expected to top $45 billion by 2032, which shows just how much everyone wants to automate everything from start to finish.
Why the rush? It’s mostly about cutting down on mistakes, saving money, and speeding things up. Some studies (Gitnux) say automation can reduce errors by as much as 70% and lets people focus on more interesting, higher-value work. So, fully automated processes—where data processing and orchestration are front and center—are quickly becoming the new normal in digital transformation, not just a nice-to-have.
Let’s see how ready our BPM engines are for this. Spoiler: not very.
“BPMN does not provide a comprehensive data model. Data Objects and Data Stores are used to show that data is required or produced, but their structure is not defined.”
— “BPMN 2.0 Handbook: Methods, Concepts, and Techniques for Business Process Modeling and Execution” (2011)
“BPMN is not intended to model data structures or detailed data flows.”
— Bruce Silver, “BPMN Method and Style” (3rd Edition, 2016)
BPMN notation was originally created as a language for describing processes and does not include data models. Everything related to data in it is limited to so-called Data Objects, which only hint that some kind of data or documents are used in the process (judging by their icon). There is also the Data Store, which pretends to be a database or some information system, again based on its appearance.
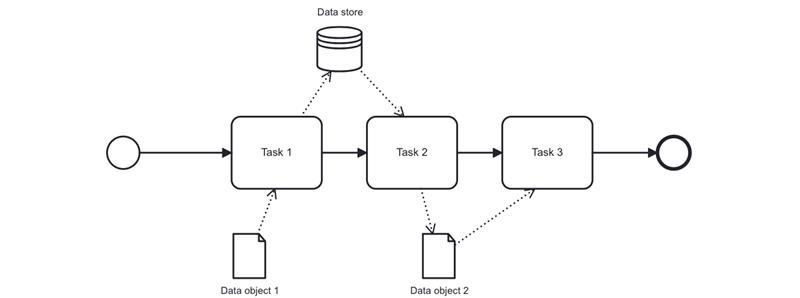
In essence, these are just graphical symbols. Their role is limited to informing the diagram reader that some data exists in the system and there is interaction with storage. There is no engine-level implementation behind them.
As a result, we have a situation where there are clear rules for modeling the process itself according to the BPMN 2.0 standard, which are implemented in a very similar way (if not identically) across engines. But there is no unified mechanism for working with data — each developer decides how to handle it on their own.
On the one hand, this is good — freedom! You can choose the optimal solution for your tasks. On the other hand, the lack of clear rules often leads to fewer than ideal data handling solutions in projects.
Why Do We Need Process Variables?
So, at the BPMN model level, we don’t have data as such — the diagram describes the structure and logic of the process but does not operate directly with variables. However, when the process is executed, data becomes necessary: somewhere you need to save user input, somewhere to make a decision, and somewhere to send a request to an external system. All this data exists in the form of process variables, which are “attached” to each process instance and accompany it throughout its execution.
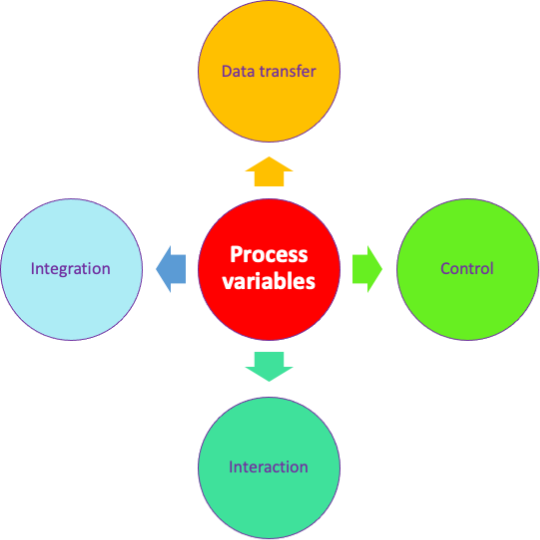
Broadly speaking, process variables fulfill four roles:
- Data transfer between steps
- Process flow control
- Interaction with the user
- Integration with external systems
Process variables help carry information through the entire process, from start to finish. For example, a user fills out a loan application form, and the data they enter (amount, term, loan purpose) is saved into variables. Then these values are used in service tasks, passed to gateways, and determine which branches should be activated. In one branch, a variable may be updated or supplemented and then passed further, for example, to a verification or notification task.
They also allow us to control the behavior of the process during execution. Suppose we have a variable called priority, calculated based on the application parameters. If, at the process start, it equals "high," the task is automatically routed to a specific specialist; otherwise, it goes into a general queue.
When the process interacts with a user, variables become the link between the form and the process logic. They are used both to display data and to receive user input. If a variable was already set on a previous step — for example, userEmail — its value can be shown in the form. The user, in turn, fills in other fields, and their values are saved back into variables to be used later in the process. Thus, the form works as a “window” into the current execution context: everything the process knows at this point is available to the user, and everything the user enters remains in the process.
Finally, process variables are a communication channel with the outside world. When a service task calls a REST API, it can use variables as input parameters and save the response to a variable. This response can then be analyzed, logged, passed to another service, or displayed to the user.
The Lifecycle of a Variable
Now let’s talk about how process variables are born, live, and end their lifecycle. To do that, we first need to look at how they are structured.
In BPM systems such as Camunda, Flowable, or Jmix BPM, process variables are objects that store not only their value but also metadata about themselves. In other words, they’re not simple variables like in Java or another programming language — they’re containers that hold data.
Why make it so complicated? Because a process can run for a long time — hours, days, or even months. That’s why the values of variables need to be stored in a database, so they can be retrieved later when needed. And if we write something to the database, metadata appears as well—it’s only logical.
Creation and Persistence of Variables
Note: The examples in this section are based on the Flowable engine.
So, data has entered the process — for example, as a payload in the start message, in the form of a Map<String, Object>. What does the engine do next? First, it creates a process instance — ProcessInstance — and initializes its execution context. Then the engine automatically saves all passed variables into this context using the setVariable method. But it’s important to understand: the engine doesn’t just “store” values somewhere in memory. It wraps each variable according to its type into an internal entity called VariableInstanceEntity, making the variables immediately accessible throughout the process — in scripts, transition conditions, tasks, and so on.
Additionally, a developer can create a variable in code whenever needed, also using the setVariable method — including from Groovy scripts:
runtimeService.setVariable(executionId, "docStatus", "APPROVED");
As long as the process hasn't reached a transaction boundary, no database writing occurs. The variable remains in an in-memory structure — a List<VariableInstanceEntity> within the ExecutionEntity. This is convenient: the next task or script can be used without hitting the database.
However, once the process hits a wait state — such as a message or signal event, timer, user task, event-based gateway, or asynchronous task — the transaction is committed, and all entities created or modified during the transaction are flushed to the database. This includes process variables, which are written to the ACT_RU_VARIABLE table.
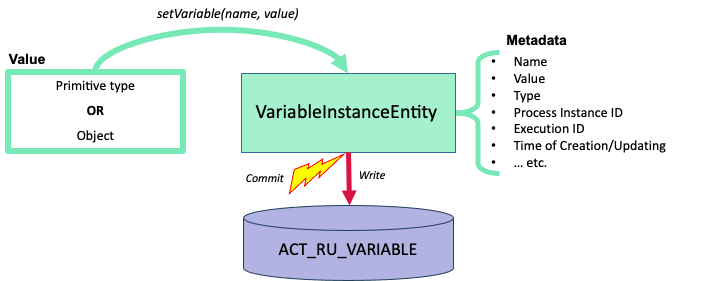
If the variable type is a primitive, it is stored as-is in the corresponding field of the table. Non-primitive variables, on the other hand, are serialized before being saved — and stored either as strings or byte arrays.
Table Fields (Translated from Russian)
| Field | Type | Purpose |
|---|---|---|
id_ |
varchar(64) |
Unique variable ID. Primary key of the table. |
rev_ |
integer |
Record version (used for optimistic locking when updating the variable). |
type_ |
varchar(255) |
Variable type (e.g., string, long, boolean, serializable, json, object, bytearray, etc.). Determines which value fields are used. |
name_ |
varchar(255) |
Variable name. |
execution_id_ |
varchar(64) |
ID of the specific execution the variable is linked to. |
proc_inst_id_ |
varchar(64) |
ID of the process the variable belongs to. Used for retrieving variables by process. |
task_id_ |
varchar(64) |
Task ID if the variable is scoped at the task level. |
scope_id_ |
varchar(255) |
Used only in CMMN. |
sub_scope_id_ |
varchar(255) |
Used only in CMMN. |
scope_type_ |
varchar(255) |
Scope type (bpmn, cmmn, dmn). Not actually used in practice. |
bytearray_id_ |
varchar(64) |
ID of the entry in the act_ge_bytearray table where the variable value is stored (if it's a byte array or a serialized object). |
double_ |
double precision |
Variable value if the type is double. |
long_ |
bigint |
Variable value if the type is long, integer, short, or boolean (as 0/1). |
text_ |
varchar(4000) |
Variable value if the type is string, json, date, or uuid. May also hold serialized values as text. |
text2_ |
varchar(4000) |
Additional text field, e.g., for serialization format or extra parameters. May be used in JSON/XML serialization. |
meta_info_ |
varchar(4000) |
Metadata about the variable, such as object class (if it's a serialized object), or other engine-relevant info. Not used in Jmix BPM. |
Once a variable is written to the ACT_RU_VARIABLE table, it becomes part of the process's persistent state. This means that even if the server is restarted, the process can be restored and resumed — along with all its variables. At this point, the cache is also cleared, and the VariableInstanceEntity objects are removed from memory.
In some cases, however, you may want a variable not to be stored in the database, for example, intermediate calculation results that aren’t needed in later steps of the process, or sensitive data like passwords, authorization tokens, and similar. In such cases, variables can be declared transient and will be kept in memory only. But this is up to the developer — by default, all variables are persistent.
Reading and Updating Variables
Now let’s take a look at how variable reading works.
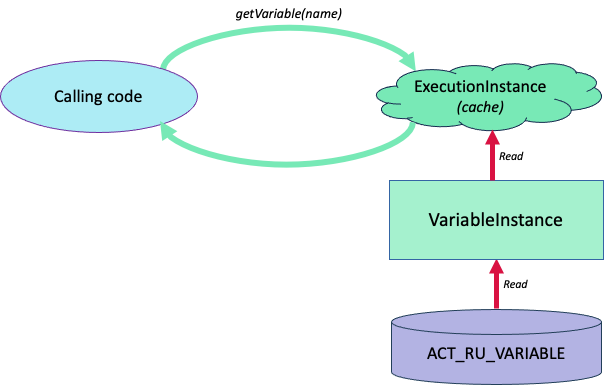
After one transaction is successfully completed, the next one begins, and a new variable cache is created. Initially, this cache is empty — variables are not loaded by default. Only when a variable is actually needed does the engine execute a command like:
String status = (String) runtimeService.getVariable(executionId, "docStatus");
First, the engine locates the corresponding ExecutionEntity using the given executionId. This is the execution context that holds variables associated with a specific active step of the process. If the variable is not yet in memory, the engine issues an SQL query to the ACT_RU_VARIABLE table. The retrieved object is then deserialized (if necessary), added to the ExecutionEntity cache, and returned to the calling code.
If you need not just the value but the full variable information including metadata, you can request a VariableInstance object:
VariableInstance statusVar = runtimeService.getVariableInstance(executionId, "docStatus");
Keep in mind, though, that this is a read-only object. If you want to update the variable, you must call setVariable again. The new value will be written to the database during the next commit. Technically speaking, this is not an update, but rather the creation of a new variable with the same name.
And here’s a subtle point: the engine does not enforce type consistency. So, if the variable originally held a string, and you later assign a number to it, the engine will accept it without complaint. However, this may lead to issues later — for example, when accessing historical data or using the variable in other steps of the process.
Deleting Variables
When a process (or execution) ends, its variables are deleted. That is, all entries in the ACT_RU_VARIABLE table associated with the specific executionId are removed.
A developer can also proactively delete a variable before the process finishes:
runtimeService.removeVariable(executionId, "largePayload");
Normally, this isn’t necessary just for “clean-up” purposes — the engine handles that on its own.
However, there are situations where proactively removing variables can be useful. For example, when a variable contains a large amount of data — say, a JSON object several megabytes in size or a high-resolution image. Keep in mind, this data is stored in the database, not in the Java process memory — so we’re not talking about garbage collection here, but about reducing database load.
If a variable contains personal or sensitive data (like temporary passwords or one-time codes) and is no longer needed after use, it should be deleted.
Some variables are used only within a single step (for example, intermediate results). These can be removed after that step finishes to avoid confusion or accidental reuse.
To avoid dealing with deletion altogether, it's often better to declare such variables as transient right from the start.
Transient means that the variable is temporary and not saved permanently (for example, not stored in a database or persisted between sessions). It exists only during the runtime or the current process and disappears afterward.
Writing to History
A key principle is that historical records for variables are not created when the process finishes, but rather at the moment the variable is set (setVariable), if history tracking is enabled. This is controlled by the historyLevel parameter.
| historyLevel | Description | What Is Stored |
|---|---|---|
none |
History is completely disabled | Nothing |
activity |
Minimal history: tracks process activity | Process start/end, tasks, events |
audit |
More detailed history | Everything from activity + variables (latest value only) |
full |
Complete history, including changes | Everything from audit + all variable changes (ACT_HI_DETAIL) |
By default, the engine uses the ```audit``` level — a compromise between useful historical data and performance.
So, in most cases, history is enabled. When a variable is created, its value is also written to the ACT_HI_VARINST table. More precisely, a HistoricVariableInstanceEntity is created and inserted into that table when the transaction is committed.
If historyLevel = full, every change to the variable is also recorded in the ACT_HI_DETAIL table.
Important Note
BPM engines do not provide a unified mechanism for working with variables. Variables can appear anywhere — as a field in user form, as a payload in a message or signal, or declared in script code, Java delegates, or Spring beans.
All of this is entirely the developer's responsibility. Your IDE won’t be able to help. That’s why extreme attentiveness is required. One day, you may want to fix a typo in a variable name — but there will be no way to automatically track down all the places where it’s used.
Scope
Like regular variables, process variables have scope. But this concept works quite differently in BPM than in programming languages. Just accept it as a fact and don’t rely on intuition — it can easily mislead you.
In programming, a variable scope is defined lexically, — depending on the class, method, or block where it is declared. It doesn’t matter whether the language uses static typing, like Java, or dynamic typing, like Python.
Process variables are something entirely different, as Monty Python might say. Essentially, they are not just variables but runtime objects. Therefore, the lexical approach doesn’t apply here. And although you can declare variables in a BPMN model, it’s not a true declaration like in programming. It’s more like a description of intent — the engine doesn’t require these variables to exist until they are actually set.
For example, in Jmix BPM, you can define process variables in the start event. Such declarations are useful for documentation purposes, so anyone reading the model understands which variables are used. And if the process is started programmatically, explicitly listing the variables helps the developer know what parameters are needed to start it.
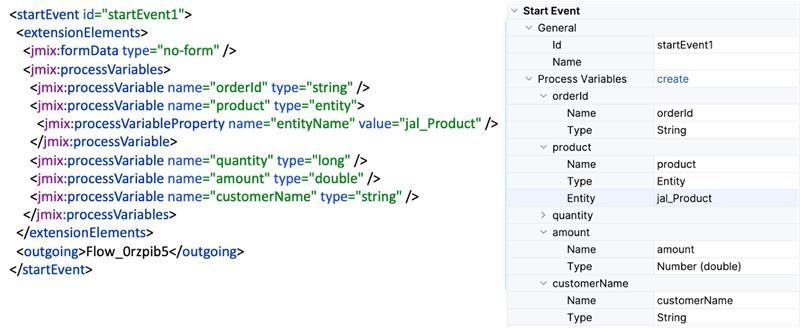
But they will not appear in the process by themselves. They must either be passed as parameters or created at some subsequent step using the setVariable method. Otherwise, if you try to access them, the system will throw an error stating that such an object does not exist.
As we discussed in the first part of this article, process variables are created as a result of calling the setVariable method. Their scope is determined by their "birthplace," almost like citizenship — that is, the execution context in which they were created.
When a process instance starts, the engine creates a root execution context (the process instance). Then, as the process progresses, these contexts form a hierarchical structure. For example, when the flow encounters an embedded subprocess, a parallel gateway, an asynchronous task, and so on, a new execution context is created. Subsequently, child contexts arise relative to previous ones. Thus, execution contexts form a tree.
Accordingly, the scope of variables is defined by the position of their execution context within this tree. Variables created in a higher-level context are visible in all the lower levels beneath them.
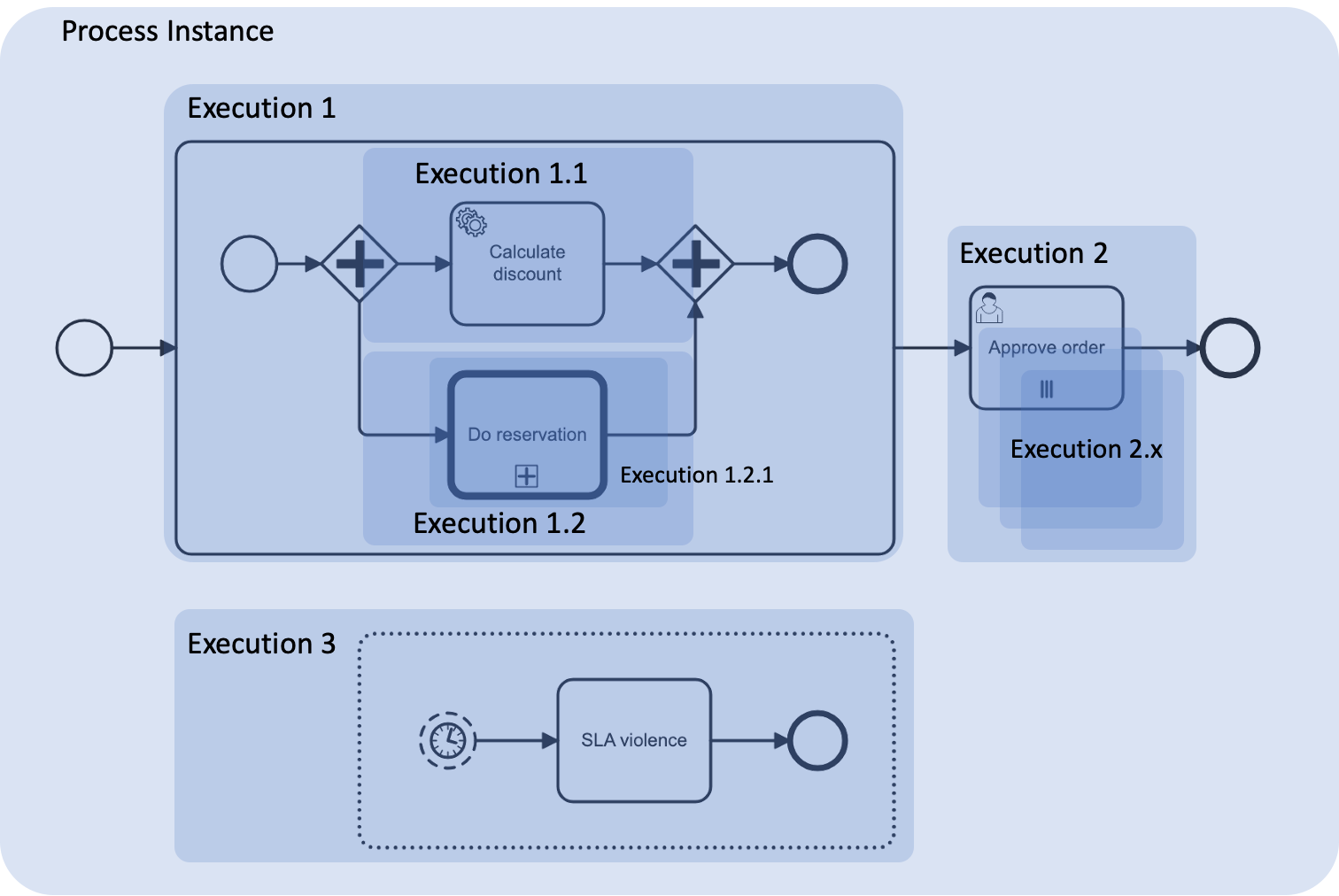
Let’s take a process as an example and mark all its execution contexts:
Then, represented as a tree, it will look like this:
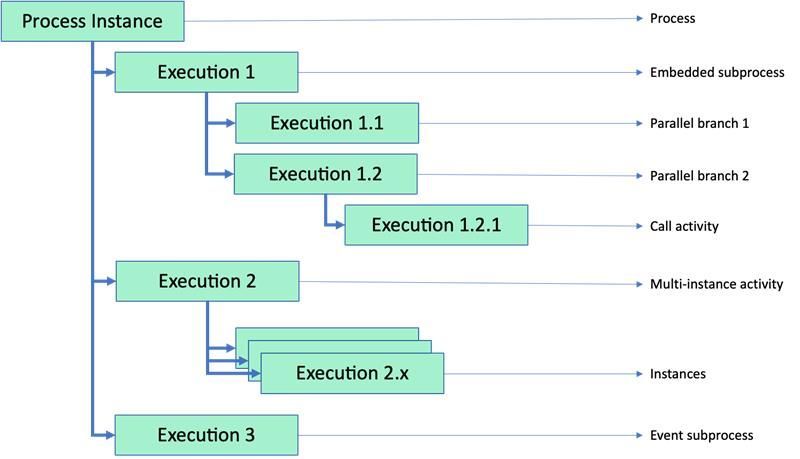
If we define the variable orderId at the top level of the process, it will be accessible everywhere. But a variable like discount, if it is set in the first parallel branch, will only be visible within its own execution context and cannot be accessed later outside of it. So, it’s important to plan variable declarations with their scope in mind.
A nested subprocess not only helps to structure execution logic but also creates a new scope — and this can actually be its more important feature.
A separate story applies to external subprocesses (call activities). Each such call is wrapped in its own execution context. That’s why in the second parallel branch we see another nested execution. But the external subprocess itself runs as a completely separate instance, and by default does not see variables of the parent process. You must explicitly map variables to pass them into the child process — and similarly map them back if needed.
If you have event subprocesses, each one lives in its own execution and waits to be activated. There are no special tricks here — it sees all process-level variables plus its own.
When a multi-instance task occurs on the path, first a common execution context is created (in our example — execution 2) which tracks all instances. Then each instance gets its own separate execution context. A common mistake here is when someone tries to write a variable at the top level from a specific instance — for example, in parallel document approvals. As a result, all approvers overwrite the same variable, and you only see the decision of the last approver. The key here is not to get confused by all these variables, which are often named the same.
This situation is resolved by local variables, which we will discuss below.
Local Variables
If you set a variable in the usual way, it will be visible to all child executions. But if you use the method setVariableLocal, it will be “locked” within the current execution and won’t be visible outside of it, including in lower-level contexts.
Okay. But why would you need to guarantee that a variable is not passed down the hierarchy?
Actually, this isn’t the main purpose. Local variables help keep things organized in your process: when you declare a variable as local, you make sure it won’t accidentally overwrite a variable with the same name in a broader (global or parent) scope.
Returning to our approval example: when in each instance of the multi-instance subprocess we explicitly specify that the comment field and the document decision are local variables, the chance of confusion is reduced.
In general, local variables are a mechanism for isolation and error prevention rather than a functional necessity. They do not solve problems that couldn’t be solved otherwise, but they do it more safely and cleanly.
Variable Shadowing
What if variables have the same names?
This can happen — you create a variable in a child execution context with the same name as one already presented in the parent. In this case, variable shadowing occurs — the parent variable becomes inaccessible in the current context, even though it still exists in the execution tree.
How it works
Each execution context contains its own set of variables. When accessing a variable via the method getVariable(String name), the engine first looks for it in the current execution. If the variable is found — it is used, even if a variable with the same name exists at a higher level. Thus, the higher-level variable is “shadowed.”
execution.setVariable("status", "CREATED");
// Inside a task or subprocess:
execution.setVariableLocal("status", "PROCESSING");
// What will a script or service see in this execution?
String currentStatus = (String) execution.getVariable("status"); // "PROCESSING"
Although the parent variable still exists, the child variable overrides it within the current execution. Once you exit the scope of the child context (for example, when the subprocess ends), the higher-level variable becomes visible again.
Variable shadowing can be useful when used correctly, but it also represents a potential source of errors. In some scenarios, it provides an advantage — for example, allowing you to temporarily override a variable without changing its original value. This is especially convenient in multi-instance constructs where each instance works with its own copy of data.
However, shadowing can lead to unexpected results if you are not sure which context, you are in. Debugging becomes more difficult: in the history, you may see a variable with the same name, but it’s not always clear at what level it was created or why its value differs.
To avoid such issues, it’s recommended to follow several guidelines. It’s better to use different variable names if they have different meanings or belong to different execution levels.
Also, consciously manage the context in which variables are created and avoid using setVariableLocal unless there is a clear need. When analyzing process state, it is helpful to check variables at the current and parent levels separately using getVariableLocal() and getParent().getVariable() to get the full picture.
Types of Process Variables
As for variable types, their variety depends on the engine developer — as mentioned earlier, the specification does not define this, so each implementation does its own thing. Of course, there is a common set that includes primitive types — strings, numbers, boolean values, as well as dates. But even here there are differences — compare the two illustrations and see for yourself.
In Camunda, we have one set of data types, while in Jmix BPM (with the Flowable engine) it is somewhat different.
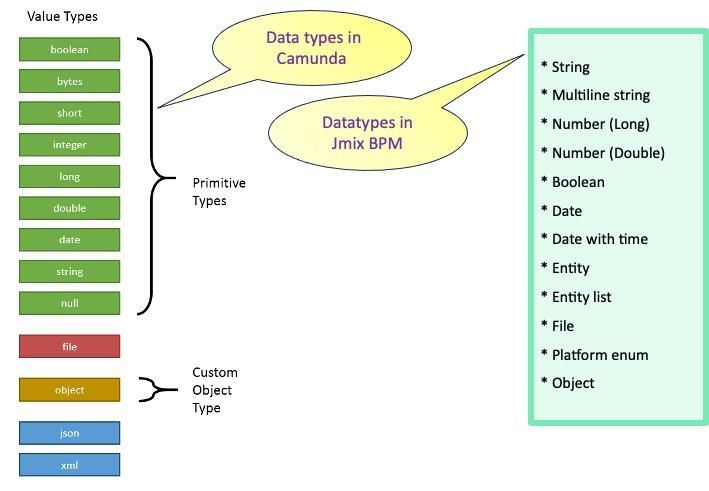
Regarding the basic types, this difference is insignificant and may only become apparent when migrating from one engine to another. But there are some interesting distinctions worth mentioning.
You’ve probably noticed that Camunda supports JSON and XML types. However, this is not a built-in feature of the engine itself — to work with them, you need a special library called Camunda Spin, designed for handling structured data within business processes. It provides a convenient API for parsing, navigating, and modifying data, as well as automatically serializing and deserializing data when passing it between tasks. This can be especially useful when processing responses from REST services, storing complex structures as variables, and generating XML/JSON documents.

In turn, Jmix BPM allows you to use elements of the Jmix platform’s data model as process variables — entities, lists of entities, and enumerated types (Enums). This is especially helpful when you need to manipulate complex business objects within a process that contains dozens of attributes. For example, applications, contracts, support tickets, and so on.
Entity Data Task — Accessing the Data Model from the Process
Jmix BPM includes a special type of task called the Entity Data task. With it, you can create new entity instances, modify them, and load individual entities or collections of entities obtained via JPQL queries directly into process variables right from the process. This is not an extension of the BPMN notation per se. Technically, these are just regular service tasks with a specific set of parameters.
Thus, you can model a process in a low-code style — using User tasks for user actions and Entity Data tasks for data manipulation. If no complex integrations or logic are required, this approach is often sufficient.
Let’s consider a hypothetical example. Suppose some data arrives. The system checks whether it relates to an existing customer order or not. Depending on the result, it executes one task or another; either creating a new Order entity or loading/finding an existing one. Then, an employee performs some work, and an Entity Data task updates the modified attributes of the entity.

Of course, a real process would be more complex — this diagram merely illustrates the concept of how you can use an Entity Data task to work with data.
Limitations
This section outlines the limitations of process variables in different BPM products.
Camunda
String Length Limitation
In Camunda, values of type String are stored in the database in a column of type (n)varchar with a length limit of 4000 characters (2000 for Oracle). Depending on the database and configured character encoding, this limit may correspond to a different number of actual characters. Camunda does not validate the string length — values are passed to the database “as is.” If the allowed limit is exceeded, a database-level error will occur. Therefore, it's the developer’s responsibility to control the length of string variables.
Context Size Limitation
Although process variables are stored in a separate database table, in practice, there is a limit to the total amount of data associated with a process instance. This limit is not so much about the physical storage but rather the internal mechanisms of serialization, memory loading, transactional handling, and other engine internals. A typical safe threshold is around 3–4 MB per process context. This includes serialized variables, internal references, events, and other metadata. The exact value depends on the DBMS, serialization format, and engine configuration.
Storing too many variables or large documents in the process context can lead to unexpected ProcessEngineExceptions due to exceeding the allowable size of a serialized object. Therefore, when working with large variables, it is recommended to stay well below this limit and conduct performance testing if needed.
In Camunda 8, there is a strict limit on the size of data (payload) that can be passed into a process instance. The total maximum size of all process variables is 4 MB, including engine internals. However, considering overhead, the safe threshold is around 3 MB.
Flowable / Jmix BPM
String Length Limitation
Flowable handles strings a bit differently: if the length of a String-type variable exceeds 4000 characters, it is automatically assigned an internal type of longString. Its value is then stored as a byte array in the ACT_GE_BYTEARRAY table, while the ACT_RE_VARIABLE table contains a reference to it. As a result, Flowable does not impose any explicit limit on string length.
In theory, the length of a string variable is only limited by the Java maximum —
Integer.MAX_VALUE = 2,147,483,647
(roughly 2.1 billion characters).
However, in practice, the effective limit is determined by available heap memory.
Entity List Size Limitation
For variables of type Entity List, there is a constraint related to the way they are stored. When saved to the database, such variables are serialized into a string format like:
<entityName>."UUID" — for example:
jal_User."60885987-1b61-4247-94c7-dff348347f93"
This string is saved in a text field with a maximum length of 4000 characters. As a result, the list can typically contain around 80 elements before exceeding the limit. However, this restriction only applies at the point of database persistence — in memory, the list can be of any size.
Context Size Limitation
Flowable (and thus Jmix BPM) does not enforce a hard limit on the size of the process context. Still, it's recommended to keep the context as small as possible, since a large number of process variables can negatively impact performance. Also, you might eventually run into limits imposed by the underlying database system.
Process Variables in Groovy Scripts
Scripts in BPMN are often underrated, yet they are a powerful tool—especially lightweight, in-process logic. They're commonly used to initialize variables, perform simple calculations, log messages, and so on. BPM engines typically support Groovy or JavaScript as scripting languages, with Groovy being more prevalent due to its concise syntax, native Java compatibility, and ease of use when working with process objects. The most important of these is the execution object, which represents the process context and allows you to work with process variables.
Your main workhorses are the familiar setVariable and getVariable methods, used to write and read process variables. However, there's a feature that—while seemingly convenient—can lead to hard-to-diagnose bugs:
process variables in Groovy scripts are accessible directly by name.
That means you can reference them in expressions without explicitly reading them first:
amount = price * quantity
But here’s the catch:
The assignment operator does not affect process variables.
So, after that expression, the value of the amount process variable will not change. To actually update it, you must explicitly call setVariable:
execution.setVariable("amount", price * quantity)
This is because a process variable is part of the execution context, not just a regular Groovy variable—it must be handled explicitly.
To complicate things further, Groovy allows you to define local script variables on the fly. Since Groovy is a dynamic language, it will silently create a new script variable if one isn't already defined. So, if you haven’t explicitly created the process variable amount, the following line will still work:
amount = price * quantity
execution.setVariable("amount", amount)
And there's more to it! Even though Groovy doesn’t require it, declaring variables explicitly using def is considered best practice. It helps avoid subtle bugs:
def amount = price * quantity
...
execution.setVariable("amount", amount)
Now everything is clean and correct. Right? — Well, almost.
When your script task is marked as asynchronous, this convenient implicit access to process variables by name might break.
Consider the following line in an asynchronous script:
execution.setVariable("counter", counter + 1L)
You might get a confusing error like:
groovy.lang.MissingPropertyException: No such property: counter for class: Script2
This means the variable counter wasn't available in the script context at execution time.
Why? Because engines like Flowable inject process variables into the script environment automatically, but for asynchronous executions, this may happen too late—after the script has already started running.
To avoid this issue, always explicitly read the variable at the start of the script:
def counter = execution.getVariable("counter")
execution.setVariable("counter", counter + 1L)
And just like that — no more exceptions!
Best Practices
Working with process variables is a key part of building reliable business processes. Variables allow the process to “remember” data, pass it between tasks, and make decisions. However, without discipline, they can easily become a source of bugs—from subtle logic errors to critical failures. This section outlines proven practices to help you avoid common pitfalls and build a clean, predictable data model in your process.
-
Use clear and unique variable names
Choose meaningful and descriptive names. Avoid duplicates.
Good: orderApprovalStatus
Bad: status
-
The fewer variables, the better
Keep in mind that the process context isn’t unlimited. Avoid creating unnecessary variables. Even without hard size limits, bloated contexts hurt performance.
Avoid storing large documents or massive JSON structures directly—store them as files and keep only a reference in the process.
-
Use transient variables for temporary data
If data is only needed within a single action or expression, define it astransient. It won’t be saved to the database or show up in history.
-
Be cautious with entity variables
Many BPM platforms support storing complex objects (e.g. entities) in process variables. This is convenient for business logic involving entity attributes.
However, if you load an entity into a variable at the start of the process, and later display it in a form days later, can you be sure it hasn’t changed? — Definitely not.
Instead, store the entity’s ID as a variable and re-fetch it when needed.
-
Serialization may surprise you
When saving complex objects, the engine serializes them before writing to the DB. Not all Java objects can be stored—your object must either implementSerializable, or you must provide and register a custom serializer.
Also, serialization may behave differently in regular vs. asynchronous tasks, since async tasks run in theJobExecutorwhich has a different context.
-
Link entities to processes
Often, a process is started in relation to an entity—an order, document, customer request, etc. You may want to navigate from the entity to its process.
Here’s a simple trick: add aprocessInstanceIdfield to your entity. No more searching with complex API queries—just follow the ID.
-
Don’t blindly pass all variables into a Call Activity
It’s tempting to tick the box that passes all variables from the parent to the subprocess. But it’s better to explicitly map only the variables you need.
Otherwise, you risk data leaks or serialization issues.
-
Configure history settings
The more variables you have, the faster your history tables will grow. All BPM engines support history cleanup mechanisms—take time to configure them.
If you need to keep historical data, create a mechanism to export it from the process DB to your own storage.
Also, be mindful of sensitive data—like credentials or API keys. They might be safe during the process but later get dumped into history with all other variables. And history access might be less secure than the live process.
So, to be safe—avoid storing sensitive variables in history.
-
Use local variables where appropriate
Technically, you can manage without local variables. But using them helps keep things organized. A clear local variable reduces the chance of errors.
However, don’t overuse them. It’s not necessary to make every child context variable local—sometimes you need them to propagate downward.
-
Avoid unnecessary variable shadowing
Variable shadowing (redefining variables in nested contexts) is mostly useful in multi-instance activities.
Outside of that, it's better to give variables unique names to prevent confusion.
-
Document your variables
BPM engines don’t manage variables, and IDEs typically don’t help with this either.
Maintain your own variable registry—describe what each variable is for and where it's used.
This will make your processes easier to maintain in the long run.
Conclusion
Managing process variables with care is essential for building robust, maintainable business processes. By following these best practices, you can avoid common pitfalls and ensure your processes remain reliable and easy to support.
Thoughtful variable management not only prevents bugs and performance issues but also makes your process models more transparent for everyone involved. In the end, a little discipline in how you handle variables goes a long way toward creating clean, predictable, and future-proof BPM solutions.





