


Introduction
Good search capabilities are always useful in any application which works with data. In CUBA, there was an add-on - “FTS” based on Lucene. For Jmix, we have re-implemented the search engine. Now we use Elasticsearch as the search engine.
Elasticsearch is based on Lucene and uses the same abstractions - docs and indexes. Since Jmix is a framework for data-centric applications, we need to create documents and build indexes based on data stored in a relational database.
In this article we will discuss approaches for Elasticsearch usage in Spring Boot and ideas that were implemented in Spring Boot-based Jmix framework.
Spring Boot Solution
Spring Boot supports Elasticsearch, there is a separate project for it.
To add Elasticsearch to our Spring Boot application, we need to define “Documents” as Java classes similar to JPA Entities. Let’s have a look at the example from the Spring documentation:
@Document(indexName="books")
class Book {
@Id
private String id;
@Field(type = FieldType.text)
private String name;
@Field(type = FieldType.text)
private String summary;
@Field(type = FieldType.Integer)
private Integer price;
// getter/setter ...
}
Here we define an indexed document, its fields and index name. In order to work with indexes, save documents and perform search, we need to create a Spring Data repository similar to this:
interface BookRepository extends Repository<Book, String> {
List<Book> findByNameAndPrice(String name, Integer price);
}
The Spring Boot API for Elasticsearch is slick and familiar for developers, but if you want to perform a search in the database, things become a bit more interesting. If we want to do that, we need to implement the following code.
For the index creation:
- Define documents with ID field and table name to link them to data
- When data is stored or updated, create a document, by copying changed data from the updated data rows
- Send this document to the Elasticsearch
For the search:
- Find a document according to search query
- Find a corresponding entity by the table name and ID
This is not hard work, but it still requires some manual coding. So, is there a way to simplify it a bit?
Jmix Solution
In Jmix, we provide a simple way for configuring Elasticsearch indexing. It will look familiar for developers who worked with BPM or Security in CUBA, and this approach won’t look strange for the experienced Spring Boot developers. Let’s have a look at the index configuration for the Book JPA entity.
@Table(name = "book")
@Entity
public class Book {
@Id
private UUID id;
private String name;
private String summary;
private Integer price;
// getter/setter ...
}
If we want to define an index to search books using Elasticsearch, we just need to define an interface and define one method:
@JmixEntitySearchIndex(entity = Book.class)
public interface BookIndexDefinition {
@AutoMappedField(includeProperties = {"name", "summary", "price"})
void bookMapping();
}
After that, the index will be created automatically at the boot-time. There are various options for index creation: you can use masks to include or exclude entity fields to/from indexes, you can include referenced entities, index uploaded files, etc. You can find more details about it in the add-on documentation
OK, the index is created, now we need to populate it. In Jmix, we set up a queue to store entity changes and an entity tracking listener. The listener tracks changes in an entity’s fields which are included into indexes and adds those changes into the queue. The third component - quartz job that updates Elasticsearch indexes.
The detailed search architecture diagram is below:
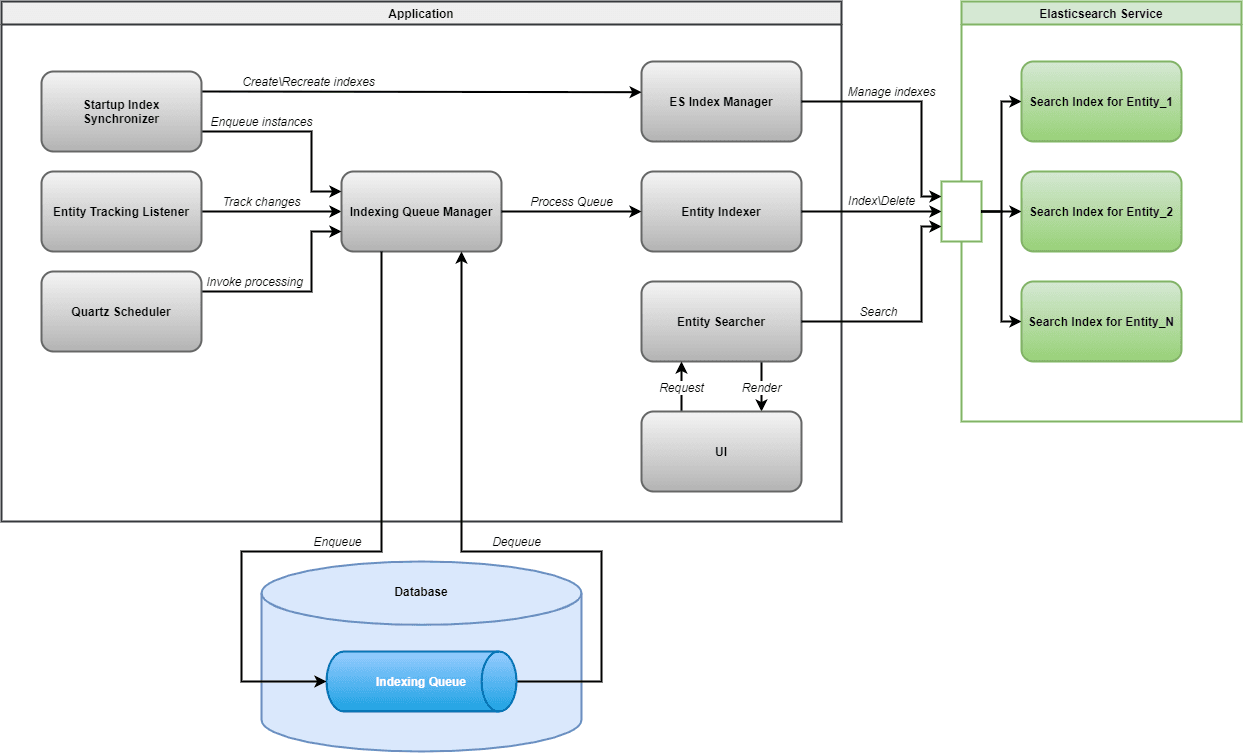
So, Jmix framework creates and updates indexes automatically. After that, we can use the EntitySearcher service that will send a query to Elasticsearch, receive results, and return corresponding entities.
Jmix search add-on is easy to set up and use, but it has some limitations: it does not allow native Elasticsearch queries, therefore, it is less flexible. So, if this functionality is required, you can add Spring Boot Elasticsearch library and use its API to execute arbitrary queries.
Using Search in the Backoffice UI
The Jmix framework provides a component that allows to perform search from the backoffice UI. Basically it is one text field similar to what we usually see in search engine web pages like google or duckduckgo, and it provides pretty advanced functionality.

In the screen descriptor it is represented by one tag:
<search:searchField id="bookSearchField" entities="Book"/>
So, this component will initiate search through all books added to the index. For example, if we have the following data set:

And start searching for the “jungle” word, the search component will open the screen which displays all books which fields contain the word.

By clicking on an entity name, we will open the editor screen for the selected entity.
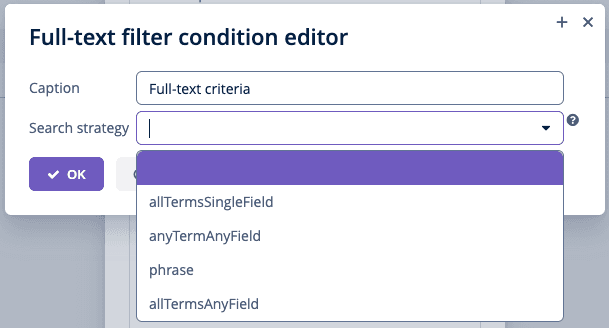
In addition to this, we can add full-text search capabilities to the generic filter. Apart from JPQL, Property and Group conditions, we can see the “Full-text condition” option. If we choose this condition, we can select a search strategy and apply it for the search string.
Conclusion
In Jmix, we keep the approach used in the previous versions: take a battle-proven framework, build an API over it and simplify usage as much as it needs to be and we don't hide implementation from a developer, from the other side.
With Jmix you can build full text search indexes for your database quickly and easily. All you need to do - define interfaces and add annotations to their methods. Automatic index data queuing and quartz jobs will do the rest. And now you can use not only Jmix’s APIs to search data, but any tool that works with Elasticsearch compatible engines as well as Jmix’s Backoffice UI.





