


Introduction
Multitenancy is a reference to the mode of operation of software where multiple independent instances of one or multiple applications operate in a shared environment. The instances (tenants) are logically isolated, but physically integrated.
You can find a nice explanation on the Internet where the multi-tenant approach is compared to office building leasing:
Apartments are a perfect example of a multi-tenant architecture. They have a centralized administration for security (at the main gate), electricity, water, and other facilities. These facilities are owned by the apartment owner and shared by the tenants.
In this article, we will reason about the multi-tenancy architecture and review one of the implementations of this approach in CUBA Platform.
A Short History of Multi-Tenancy
Let us start from a completely different topic - software distribution and deployment. Initially software was distributed using physical media - tapes, discs, flash drives. And usually you had to deploy the software to the server that was installed in the local network. Communication channels back those days were not as good as they are now.
But gradually the internet bandwidth grew up, and now we’re talking about megabit- and gigabit-wide channels. So, it became much easier to deliver software via the internet - downloading a hundred megabytes takes less time than going to a store to buy a DVD or a Blu-ray disc with the software.
Meanwhile, communication channels and computing hardware development caused a new market to emerge - virtualization, and later - IaaS (infrastructure as a service). It became easier to set up a server with a pre-installed software product and give access to users.
As a result, vendors adopted SaaS - “software-as-a-service” distribution model. You, as a client, just had to buy access to a software product deployed. You didn’t need to maintain local servers, so TCO was lower.
Installing a software instance for each client was still not an easy operation, so software developers started to use the multi-tenant architecture to simplify deployment and maintenance. You still can see a lot of SaaS deployments on the internet. For example, Salesforce started using a multi-tenant approach and SaaS distribution a long time ago.
But implementing multi-tenant applications is a challenging task. You have to think about separating customer’s data, cooperative resource consumption, common data sharing and other things. The latest respone to these challenges is the PaaS (platform-as-a-service) model.
Containerization and DevOps processes development are the main threats for multi-tenant applications. Today it is very easy to start a new “server” or even a whole “infrastructure”, including database, application services, caching servers and reverse proxy, thanks to such products as Docker and Kubernetes. For developers, it is much simpler to implement a single-tenant application and then deploy a new instance of it for every new client, literally, in seconds and even happens in a fully automated way. Sometimes it might lead to another phenomenon called “cube sprawl” though, but there is no “silver bullet” in this world.
Nevertheless, multi-tenant applications are still a big deal as for today (see Salesforce, Work Day, Sumo Logic, etc.), and still, there is a request for developing such products. Let’s review some approaches to implementing multi-tenancy and then see what CUBA Platform can offer in this area.
Multi-tenancy implementations
There are three main multi-tenancy model types applied to building a multi-tenant datastore:
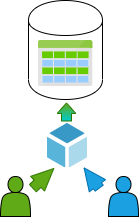
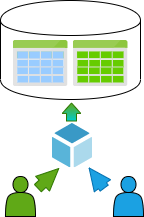
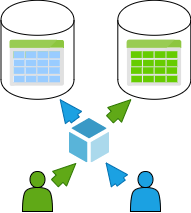
Advantages and disadvantages of multi-tenancy
There are a number of pros and cons for the multi-tenant architecture:
Pros:
- Costs. It is usually less expensive compared to other solutions.
- Simplified maintenance - administrators should monitor, patch, upgrade, and tune only one system.
- Easily scalable - adding a new tenant is a standardized, quick, and simple process.
Cons:
- Creating a multi-tenant application is a more complex task compared to a single-tenant one.
- Flexibility might be an issue, especially for applications shared by customers from different counties. There may be different requirements for personal data protection, business logic calculation, etc.
- “Nosy neighbor” problem. Another tenant may access your data or consume your resources.
- And the “single point of failure” problem. If all clients share the same resource (e.g. database), all of them are affected if this resource becomes unavailable.
Multitenancy in CUBA
CUBA framework allows us to change generated queries to the database on the fly, that’s how row-based security is implemented. And it was pretty easy to extend this mechanism for multi-tenancy applications support and implement an add-on.
When you implement a multi-tenant application using CUBA, you need to decide which entities will store tenant-specific data. As an example, let’s take the “PetClinic” sample application. The data model for the application is represented in the diagram below.
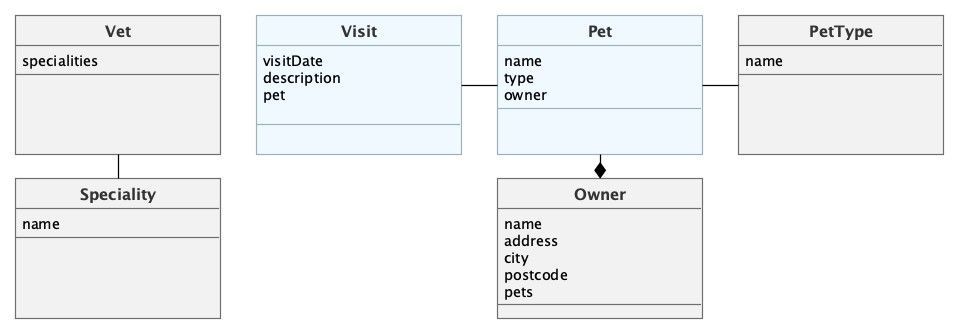
You can make all entities tenant-specific, but there is another option - make some reference entities shared. We can say that veterinarian specialties and pet types are “safe” in terms of sharing between different clients. We can tell the same about some other “common” data, e.g. list of countries in the world, etc. This will allow us to save some space and ensure that “standard” data will remain the same for all tenants, so we can rely on it when implementing the business logic.
If you want your entity to support multi-tenancy in CUBA, you need to implement a special interface - com.haulmont.cuba.core.entity.TenantEntity. After that, the add-on will take the special column for tenant separation into account. For example, here is the code fragment form Pet entity:
public class Pet extends NamedEntity implements TenantEntity {
@TenantId
@Column(name = "TENANT_ID")
protected String tenantId;
@NotNull
@Column(name = "IDENTIFICATION_NUMBER", nullable = false)
protected String identificationNumber;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TYPE_ID")
protected PetType petType;
Please note that all “system” CUBA entities support multi-tenancy by default. So you will get all users, roles, saved filters, security groups, etc. separated for each client.
After entities are created, CUBA will add an extra condition “where tenant_id =
For example, if we want to select pets and owners from the petclinic database, the final query will look like this:
SELECT *
FROM PETCLINIC_PET t1
LEFT OUTER JOIN PETCLINIC_OWNER t0
ON ((t0.ID = t1.OWNER_ID)
AND (t0.TENANT_ID = t1.TENANT_ID))
LEFT OUTER JOIN PETCLINIC_PET_TYPE t2
ON (t2.ID = t1.TYPE_ID)
WHERE ((t1.TENANT_ID = 'clinic_one') AND (t1.DELETE_TS IS NULL))
Please note the following conditions in the query: AND (t0.TENANT_ID = t1.TENANT_ID)) and (t1.TENANT_ID = 'clinic_one'). Those are conditions that CUBA adds implicitly.
But is there a way to transparently apply multi-tenancy on the database level in addition to the application level? One of the answers is Citus.
Citus: multi-tenancy for PostgreSQL
As it is said in the description: “Citus is basically worry-free Postgres that is built to scale out. It’s an extension to Postgres that distributes data and queries in a cluster of multiple machines. As an extension (rather than a fork), Citus supports new PostgreSQL releases, allowing users to benefit from new features while maintaining compatibility with existing PostgreSQL tools.
Citus horizontally scales PostgreSQL across multiple machines using sharding and replication. Its query engine parallelizes incoming SQL queries across these servers to enable human real-time (less than a second) responses on large datasets.”
And it looks like Citus resolves a lot of challenges connected with creating multi-tenant applications. It allows us to use the approach “separate database per tenant” and it “looks” like a single database for the application. All the queries are modified according to rules defined during Citus cluster creation.
It means that you can use CUBA multi-tenant implementation and get physically separated databases without rewriting queries. Let’s have a closer look at the Citus database creation process.
First, you need to create a database cluster and add nodes to it. The cluster consists of the coordinator node and worker nodes. Each worker node stores tenant-specific data, and the coordinator will reroute queries according to the “tenant_id” column. The application sends queries to the coordinator only. The process is on the picture below (taken from the Citus DB documentation):
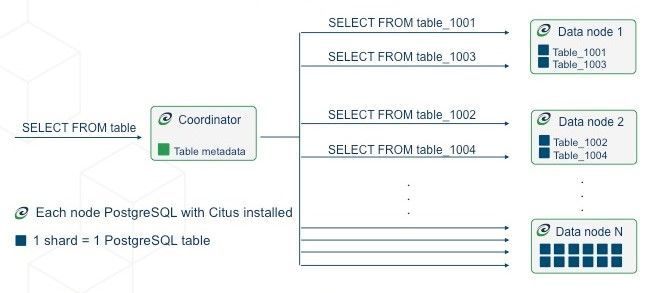
Also, to work with Citus, you need to define table types during database creation. There are three of them:
- Distributed. Those are the tables partitioned between worker nodes. They contain tenant-specific data.
- Reference tables - tables that store information that can be used by all tenants. As for the PetClinic example - those will be “Specialty” and “Pet Type”.
- Local tables. Service tables that are not used in join queries with distributed or reference tables. As an example - Cituses’ own metadata tables stored on the coordinator node.
Enterprise version of Citus allows separating tenant’s data explicitly by assigning the following operator:
SELECT isolate_tenant_to_new_shard('table_name', 'tenant_id');
And this will replace hash-based partitioning that is used by default.
Using Citus with CUBA
For the CUBA application, we don’t need to rewrite the application’s code, but the database and table creation process should be modified to be “Citus-compatible”. We all love CUBA for its SQL generation magic, but unfortunately, you have to create some scripts manually to support Citus.
The database creation process is changed. You need to create Citus extension, add nodes, and enable replication:
CREATE EXTENSION citus;
SELECT * from master_add_node('localhost', 9701);
SELECT * from master_add_node('localhost', 9702);
SET citus.replication_model = 'streaming';
The good thing is that you can develop an application on the local “ordinary” PostgreSQL most of the time and add Citus-specific table creation scripts only before deploying to the staging or production (if you are brave enough not to use staging) environment. The only thing that changes is the database address - instead of the dev local database, you need to specify the Citus cluster coordinator database address.
As for the database creation and update, you need to specify distributed tables explicitly (table name and partition column) like this:
SELECT create_distributed_table('petclinic_vet', 'tenant_id');
SELECT create_distributed_table('petclinic_owner', 'tenant_id');
SELECT create_distributed_table('petclinic_pet', 'tenant_id');
SELECT create_distributed_table('petclinic_visit', 'tenant_id');
And a similar process should be applied for the reference tables:
SELECT create_reference_table('petclinic_specialty');
SELECT create_reference_table('petclinic_vet_specialty_link');
SELECT create_reference_table('petclinic_pet_type');
In order to improve performance, you can add table colocation in addition to partitioning. But from the CUBA side - you don’t need to change anything, multi-tenancy is an absolutely transparent process.
That’s it. With the minimum efforts, we can scale the PetClinic application horizontally and use multi-tenancy on the database level, too. All the complexity is hidden in the framework and Citus plugin.
Conclusion
Creating multi-tenant applications might be a challenging job. You should consider all options before starting implementing such an approach. And technology is only one part of the equation: you need to consider license costs, cloud services tariffs, maintainability, scalability, etc. Nowadays, the PaaS model along with containerization and proper DevOps processes looks more appealing than “traditional” multi-tenant architecture, but demand on such applications is still noticeable.
If you decide to go forward with multi-tenancy, ensure that your application meets all security requirements, e.g. GDPR, HIPAA, etc. Some of them may explicitly prohibit storing data in the same database, so you’ll need to use a “separate database” approach to satisfy those requirements.
And remember that tools matter. Proper development frameworks and data management systems that support multi-tenancy architecture out of the box may greatly simplify development and prevent a lot of typical issues connected with multi-tenancy architecture.