


If you have developed at least one project on CUBA Platform or even spent a few hours discovering it you have probably noticed a strong intention to move a lot of things to runtime: role and row level security (CRUD permissions over entities and their attributes, screens and their elements, access to the row-level data), dynamic attributes (implementation for the EAV approach), entity log (for auditing all changes over entities), JMX console (for remote application maintenance), scheduled tasks (for managing repetitive tasks, such as cache updates or e-mail queue processing) and so on. Simply saying, everything that could be managed from runtime is designed in this way.
Such runtime centric approach gives great flexibility for maintaining an application on the fly. For example, if there is a need to disable some CRUD actions for a certain user or add a few properties to an entity, it will not require a long chain of development, testing and redeployment procedures.
Looks great, however, sometimes an application requires to have some of these runtime-defined features by design. Let's take a real-world example from my practice: we have thousands of sensors (installed in fields to measure some metrics of remote equipment) sending tons of raw data every second. Before it goes available for other services (other CUBA applications, that consume this information) this data must be preprocessed (using statistical algorithms to clean up the dataset from measurement noise). This raw data is being processed once an hour by a scheduled task. In this certain case, if we forget to set up the preprocessing scheduled task at runtime, the solution simply will not do its main job - supply data to other microservices. So, the scheduled task should be there by design and not set up occasionally, on demand.
SQL Scripts
The first and the most straightforward solution we had taken is putting all required scheduled tasks into the initialization SQL scripts, which will be executed on server startup. So, we set up everything we need in a staging server, use the standard functionality of the CUBA Platform to generate insert statements (see the animation below) and copy-paste them to the initialization and update scripts. The rest will be handled by the platform itself as it is described in this chapter of the documentation.
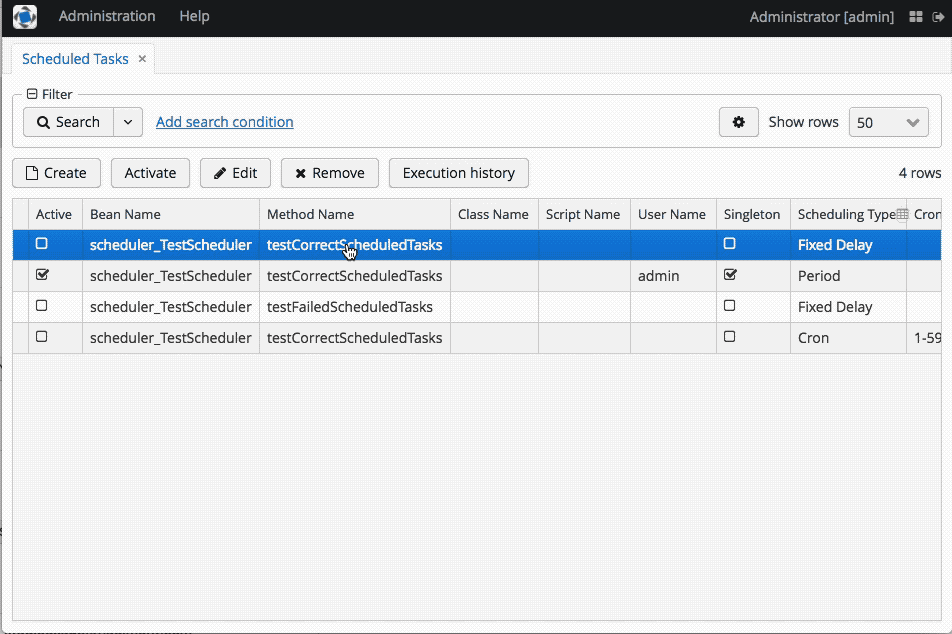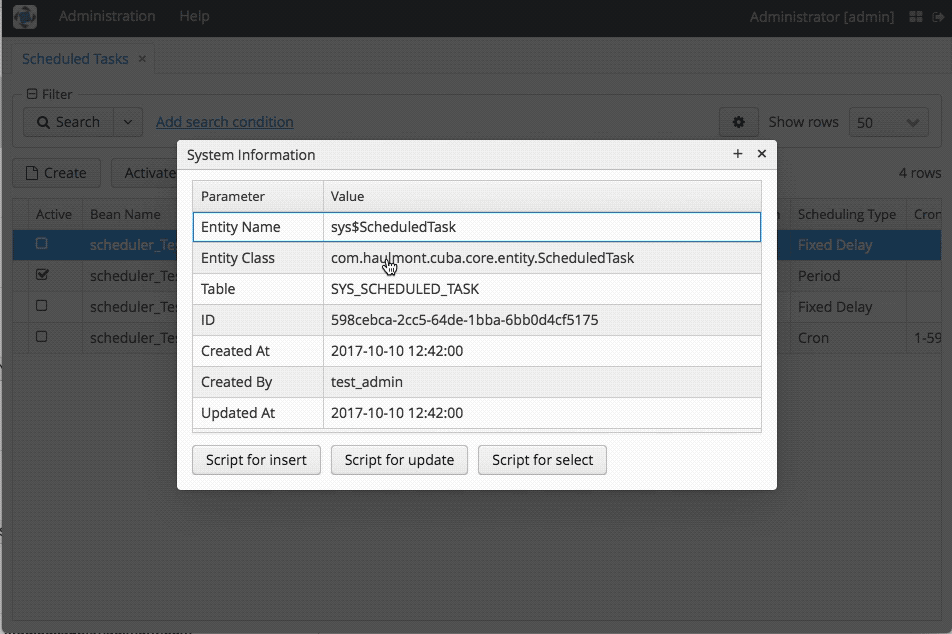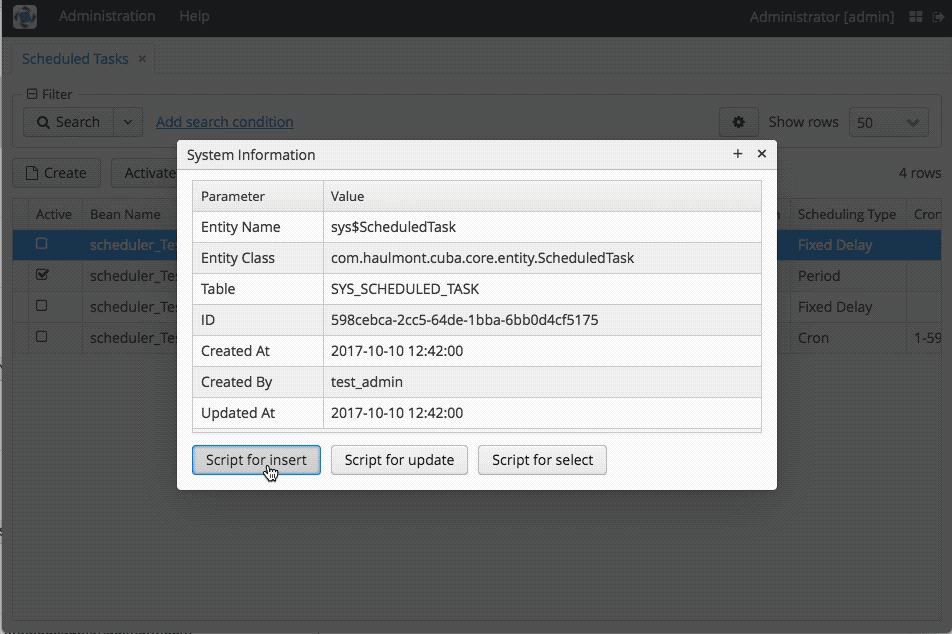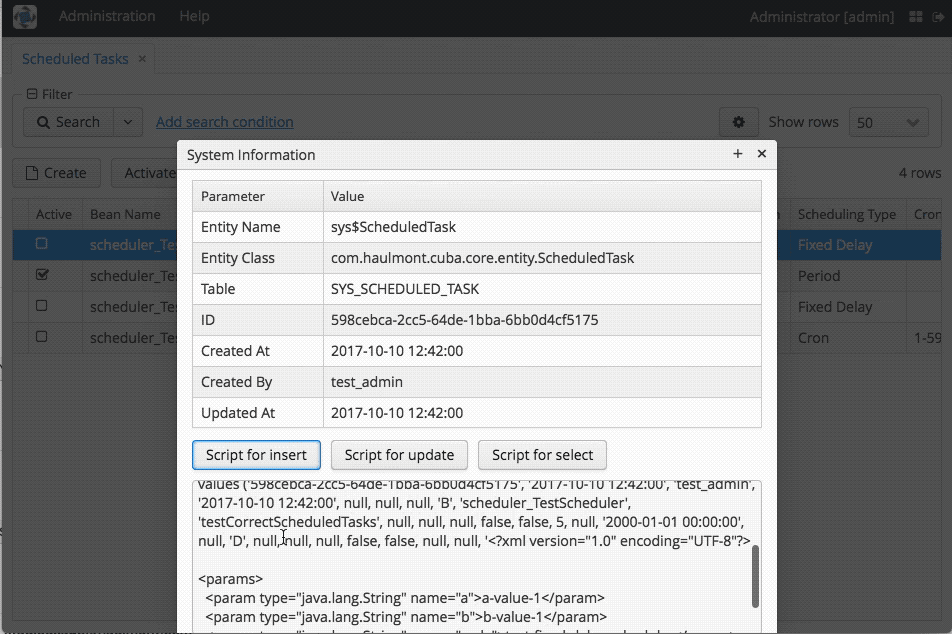
This solution worked absolutely fine, except for a few things.
SQL scripts are not any good in terms of further support. For instance, if we refactor the names of our classes or methods or even method parameters, we will need to adjust manually all scripts of the following type:
insert into SYS_SCHEDULED_TASK
(ID, CREATE_TS, CREATED_BY, UPDATE_TS, UPDATED_BY, DELETE_TS, DELETED_BY, DEFINED_BY, BEAN_NAME, METHOD_NAME, CLASS_NAME, SCRIPT_NAME, USER_NAME, IS_SINGLETON, IS_ACTIVE, PERIOD, TIMEOUT, START_DATE, CRON, SCHEDULING_TYPE, TIME_FRAME, START_DELAY, PERMITTED_SERVERS, LOG_START, LOG_FINISH, LAST_START_TIME, LAST_START_SERVER, METHOD_PARAMS, DESCRIPTION)
values ('880db2c6-f2dc-ab8d-3b5a-ebe5544c25d2', '2017-10-10 12:41:59', 'test_admin', '2017-10-10 12:41:59', null, null, null, 'B', 'scheduler_TestScheduler', 'testCorrectScheduledTasks', null, null, 'admin', true, true, 5, 5, '2000-01-01 00:00:00', null, 'P', 10, null, 'localhost:8080/scheduler-core', true, true, null, null, '
a-value
b-value
test-periodical-scheduler
', 'Test periodical scheduler');
Imagine if you have 10, 15 or a hundred of such statements...
Another problem we had is that looking at the sources, developers do not understand the importance of methods which are specified in a scheduled task for repetitive execution. We even had situation when a few such methods have been removed by a developer, because the IDE marked them as unused :). I have to notice that the IDE was absolutely right, as well as the developer, who simply wanted to clean up the source code from unused artifacts. This particular situation made me rethink the way of SQL statements.
Annotations
We had to come up with a transparent way to define scheduled tasks, so that we can refactor the source code without the risk to break them down. In response to these requirements we decided to take the very well known approach of annotations, which has originally been designed in Java exactly for this purpose, to move configurations from separate files (for example XML configurations) into inline declarations, making the source code very readable and transparent for developers.
Let me share the result of how we define scheduled tasks at design time now:
@Component
public class TestScheduler implements TestSchedulerInterface {
@Inject
private Logger log;
@Override
@ScheduledBeanMethod(
code = "test_scheduler",
isSingleton = true,
isActive = true,
period = @Period(period = 5,
startDate = "01/01/2000 00:00:00"),
logStart = true,
methodParams = {
@MethodParam(name = "a", value = "a-value"),
@MethodParam(name = "b", value = "b-value")
}
)
public void testPeriodMethod(String a, String b) {
log.debug("test method executed with parameters: {}, {}", a, b);
}
}
Now, to define a scheduled task, a developer simply marks a method of a bean with the @ScheduledBeanMethod annotation. This annotation will be read at the server startup by an annotation loader which will create the corresponding scheduled task in CUBA. The result will not be any different from if you would create it manually in the standard CUBA way, but now you can be sure that nobody will forget to create it and nobody will remove this part of code as unused.
How it Works Under the Hood
First, we need to find all the annotated methods, which is done by the ScheduledTaskLoader bean. It implements the standard BeanPostProcessor Spring interface, which gives you a hook to post process Spring beans right after their initialization. So, using the following code we gather all beans with the @ScheduledBeanMethod annotated methods into one collection:
<div style="overflow-x: scroll;">
@Component
public class ScheduledTaskLoader implements BeanPostProcessor {
...
private List<ScheduledMethodContext> scheduleAnnotatedMethods = new ArrayList<>();
...
@Overrid
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
/**
* The method scans all beans, that contain methods, annotated as {@link ScheduledBeanMethod}
*/
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Class<?> targetClass = AopUtils.getTargetClass(bean);
Map<Method, Set<ScheduledBeanMethod>> annotatedMethods = MethodIntrospector.selectMethods(targetClass,
(MethodIntrospector.MetadataLookup<Set<ScheduledBeanMethod>>) method -> {
Set<ScheduledBeanMethod> scheduledMethods = AnnotatedElementUtils.getMergedRepeatableAnnotations(
method, ScheduledBeanMethod.class, ScheduledBeanMethods.class);
return (!scheduledMethods.isEmpty() ? scheduledMethods : null);
});
for (Map.Entry<Method, Set<ScheduledBeanMethod>> entry : annotatedMethods.entrySet()) {
scheduleAnnotatedMethods.add(new ScheduledMethodContext(beanName, entry.getKey(), entry.getValue()));
}
return bean;
}
}
</div>
Another thing here I would like to pay attention to is that the @ScheduledBeanMethod annotation is designed to be repeatable (as long as you might want to schedule the same method a number of times with different input parameters or other scheduling settings; see an example in the integration tests here), so we use the AnnotatedElementUtils#getMergedRepeatableAnnotations method to get all of them.
So, after Spring initialized all its beans our ScheduledTaskLoader already knows which methods should be wrapped into Scheduled Tasks. The only thing left is to create the corresponding instances of the system ScheduledTask entity right after application startup. This can be implemented in the same way as it is shown in this recipe from the CUBA Platform cookbook:
@Component("scheduler_AppLifecycle")
public class AppLifecycle implements AppContext.Listener {
@Inject
private ScheduledTaskLoader taskLoader;
@Inject
private Authentication auth;
@Override
public void applicationStarted() {
auth.withUser(null, () -> {
taskLoader.loadScheduledMethods();
return null;
});
}
…
@PostConstruct
public void postConstruct() {
AppContext.addListener(this);
}
}
So, as you see it's not rocket science, but very effective. The same hook at startup can be used for solving variety of tasks at the startup stage, for example, sample data generation for testing and debugging or self-registering a service instance in a service registry to be become discoverable for others if you use the microservice architecture.
Summary
In conclusion, I would like to share my solution with the members of the CUBA community who have faced with the same or similar experience as I highlighted in this article. This is an application component, which means that you can easily attach it to any of your CUBA projects following this guide.
Finally, If you have something to contribute or even publish your own application component making our ecosystem better you are very welcome to contact us via the support forum or drop a message from here. In case you already created some open source app components, we recommend to mark them with the cuba-component tag, so they become available through this link on GitHub.