





“It works on my local machine!” Nowadays it sounds like a meme, but the problem “development environment vs production environment” still exists. As a developer, you should always keep in mind that your application will start working in the production environment one day. In this article, we will talk about some CUBA-specific things that will help you to avoid problems when your application will go to production.
Coding Guidelines
Prefer Services
Almost every CUBA application implements some business logic algorithms. The best practice here is to implement all business logic in CUBA Services. All other classes: screen controllers, application listeners, etc. should delegate business logic execution to services. This approach has the following advantages:
- There will be only one implementation of the business logic in one place
- You can call this business logic from different places and expose it as a REST service.
Please remember that business logic includes conditions, loops, etc. It means that service invocations ideally should be a one-liner. For example, let’s assume that we have the following code in a screen controller:
Item item = itemService.findItem(itemDate);
if (item.isOld()) {
itemService.doPlanA(item);
} else {
itemService.doPlanB(item);
}
If you see code like this, consider moving it from the screen controller to the itemService as a separate method processOldItem(Date date) because it looks like a part of your application’s business logic.
Since screens and APIs can be developed by different teams, keeping business logic in one place will help you to avoid application behavior inconsistency in production.
Be Stateless
When developing a web application, remember that it will be used by multiple users. In the code, it means that some code can be executed by multiple threads at the same time. Almost all application components: services, beans as well as event listeners are affected by multithreading execution. The best practice here is to keep your components stateless. It means that you should not introduce shared mutable class members. Use local variables and keep the session-specific information in the application store that is not shared between users. For example, you can keep a small amount of serializable data in the user session.
If you need to share some data, use the database or a dedicated shared in-memory storage like Redis.
Use Logging
Sometimes something goes wrong in production. And when it happens, it is quite hard to figure out what exactly caused the failure, you cannot debug the application deployed to prod. To simplify further work for yourself, your fellow developers and support team and to help understand the issue and be able to reproduce it, always add logging to the application.
In addition, logging plays the passive monitoring role. After application restart, update or reconfiguration an administrator usually looks at logs to make sure that everything has started successfully.
And logging may help with fixing issues that may happen not in your application, but in the services that your application is integrated with. For instance, to figure out why a payment gateway rejects some transactions, you may need to record all the data and then use it during your talks with the support team.
CUBA uses a proven package of the slf4j library as a facade and logback implementation. You just need to inject the logging facility to your class code and you’re good to go.
@Inject
private Logger log;
Then just invoke this service in your code:
log.info("Transaction for the customer {} has succeeded at {}", customer, transaction.getDate());
Please remember that log messages should be meaningful and contain enough information to understand what has happened in the application. You can find a lot more logging tips for Java applications in the article series “Clean code, clean logs”. Also, we’d recommend having a look at the “9 Logging Sins” article.
Also, in CUBA we have performance statistics logs, so you can always see how the application consumes a server’s resources. It will be very helpful when customer’s support starts receiving users’ complaints about the application being slow. With this log in hands, you can find the bottleneck faster.
Handle Exceptions
Exceptions are very important because they provide valuable information when something goes wrong in your application. Therefore, rule number one - never ignore exceptions. Use log.error() method, create a meaningful message, add context and stack trace. This message will be the only information that you will use to identify what happened.
If you have a code convention, add the error handling rules section into it.
Let’s consider an example - uploading a user’s profile picture to the application. This profile picture will be saved to the CUBA’s file storage and file upload API service.
This is how you must not deal with an exception:
try {
fileUploadingAPI.putFileIntoStorage(uploadField.getFileId(), fd);
} catch (Exception e) {}
If an error occurs, nobody will know about it and users will be surprised when they don’t see their profile picture.
This is a bit better, but far from ideal.
try {
fileUploadingAPI.putFileIntoStorage(uploadField.getFileId(), fd);
} catch (FileStorageException e) {
log.error (e.getMessage)
}
There will be an error message in logs and we will catch only particular exception classes. But there will be no information about context: what was the file’s name, who tried to upload it. Moreover, there will be no stack trace, so it will be quite hard to find where the exception occurred. And one more thing - a user won’t be notified about the issue.
This might be a good approach.
try {
fileUploadingAPI.putFileIntoStorage(uploadField.getFileId(), fd);
} catch (FileStorageException e) {
throw new RuntimeException("Error saving file to FileStorage", e);
}
We know the error, do not lose the original exception, add a meaningful message. The calling method will be notified about the exception. We could add the current user name and, probably, the file name to the message to add a bit more context data. This is an example of the CUBA web module.
In CUBA applications, due to their distributed nature, you might have different exception handling rules for core and web modules. There is a special section in the documentation regarding exception handling. Please read it before implementing the policy.
Environment Specific Configuration
When developing an application, try to isolate environment-specific parts of the application’s code and then use feature toggling and profiles to switch those parts depending on the environment.
Use Appropriate Service Implementations
Any service in CUBA consists of two parts: an interface (service API) and its implementation. Sometimes, the implementation may depend on the deploy environment. As an example, we will use the file storage service.
In CUBA, you can use a file storage to save files that have been sent to the application, and then use them in your services. The default implementation uses the local file system on the server to keep files.
But when you deploy the application to the production server, this implementation may not work well for cloud environments or for the clustered deployment configuration.
To enable environment-specific service implementations, CUBA supports runtime profiles that allow you to use a specific service depending on the startup parameter or the environment variable.
For this case, if we decide to use Amazon S3 implementation of the file storage in production, you can specify the bean in the following way:
<beans profile="prod">
<bean name="cuba_FileStorage" class="com.haulmont.addon.cubaaws.s3.AmazonS3FileStorage"/>
</beans>
And S3 implementation will be automatically enabled when you set the property:
spring.profiles.active=prod
So, when you develop a CUBA application, try to identify environment-specific services and enable proper implementation for each environment. Try not to write code that looks like this:
If (“prod”.equals(getEnvironment())) {
executeMethodA();
} else {
executeMethodB();
}
Try to implement a separate service myService that has one method executeMethod() and two implementations, then configure it using profiles. After that your code will look like this:
myService.executeMethod();
Which is cleaner, simpler and easier to maintain.
Externalize Settings
If possible, extract application settings to properties files. If a parameter can change in the future (even if the probability is low), always externalize it. Avoid storing connection URLs, hostnames, etc. as plain strings in the application’s code and never copy-paste them. The cost of changing a hardcoded value in the code is much higher. Mail server address, user’s photo thumbnail size, number of retry attempts if there is no network connection - all of these are examples of properties that you need to externalize. Use configuration interfaces and inject them into your classes to fetch configuration values.
Utilize runtime profiles to keep environment-specific properties in separate files.
For example, you use a payment gateway in your application. Of course, you should not use real money for testing the functionality during development. Therefore, you have a gateway stub for your local environment, test API on the gateway side for the pre-production test environment and a real gateway for the prod. And gateway addresses are different for these environments, obviously.
Do not write your code like this:
If (“prod”.equals(getEnvironment())) {
gatewayHost = “gateway.payments.com”;
} else if (“test”.equals(getEnvironment())) {
gatewayHost = “testgw.payments.com”;
} else {
gatewayHost = “localhost”;
}
connectToPaymentsGateway(gatewayHost);
Instead, define three properties files: dev-app.properties, test-app.properties and prod-app.properties and define three different values for the database.host.name property in these.
After that, define a configuration interface:
@Source(type = SourceType.DATABASE)
public interface PaymentGwConfig extends Config {
@Property("payment.gateway.host.name")
String getPaymentGwHost();
}
Then inject the interface and use it in your code:
@Inject
PaymentGwConfig gwConfig;
//service code
connectToPaymentsGateway(gwConfig.getPaymentGwHost());
This code is simpler and does not depend on the environments, all settings are in property files and you should not search for them inside your code if something is changed.
Add Network Timeouts Handling
Always consider service invocations via network as unreliable. Most of the current libraries for web service invocations are based on the synchronous blocking communication model. It means that the application pauses until the response is received if you invoke a web service from the main execution thread.
Even if you execute a web service call in a separate thread, there is a chance that this thread will never resume execution due to a network timeout.
There are two types of timeouts:
- Connection timeout
- Read timeout
In the application, those timeout types should be handled separately. Let’s use the same example as in the previous chapter - a payment gateway. For this case the read timeout might be significantly longer than the connection one. Bank transactions can be processed for quite a long time, tens of seconds, up to several minutes. But connection should be fast, therefore, it is worth setting the connect timeout here up to 10 seconds, for instance.
Timeout values are good candidates to be moved to property files. And always set them for all your services that interact via a network. Below is an example of a service bean definition:
<bean id="paymentGwConfig" class="com.global.api.serviceConfigs.GatewayConfig">
<property name="connectionTimeout" value="${xxx.connectionTimeoutMillis}"/>
<property name="readTimeout" value="${xxx.readTimeoutMillis}"/>
</bean>
In your code, you should include a special section that deals with the timeouts.
Database Guidelines
A database is a core of almost any application. And when it comes to production deploy and update, it is very important not to break the database. In addition to this, the database workload on a developer’s workstation is obviously different from the production server. That’s why you might want to implement some practices described below.
Generate Scripts Specific for the Environment
In CUBA, we generate SQL scripts for both creating and updating the application’s database. And after the first database creation on the production server, as soon as the model changes, the CUBA framework generates update scripts.
There is a special section regarding the database update in production, please read it before going to production for the first time.
Final advice: always perform the database backup before updating. This will save you a lot of time and nerves in case of any problem.
Take Multitenancy into Account
If your project is going to be a multi-tenant application, please take it into account at the beginning of the project.
CUBA supports multitenancy via the add-on, it introduces some changes to the application’s data model and the database’s queries logic. As an example, a separate column tenantId is added to all Tenant-specific entities. Therefore, all queries are implicitly modified to use this column. It means that you should consider this column when writing native SQL queries.
Please note that adding multi-tenancy capabilities to an application that works in production might be tricky due to the specific features mentioned above. To simplify migration, keep all custom queries in the same application layer, preferably in services or in a separate data access layer.
Security Considerations
When it comes to an application that can be accessed by multiple users, security plays an important role. To avoid data leaks, unauthorized access, etc. you need to consider security seriously. Below you can find a couple of principles that will help you to improve the application in terms of safety.
Secure Coding
Security starts with the code that prevents issues. You can find a very good reference regarding secure coding provided by Oracle here. Below you can find some (maybe obvious) recommendations from this guide.
Guideline 3-2 / INJECT-2: Avoid dynamic SQL
It is well known that dynamically created SQL statements including untrusted input are subject to command injection. In CUBA, you may need to execute JPQL statements, therefore, avoid dynamic JPQL too. If you need to add parameters, use proper classes and statement syntax:
try (Transaction tx = persistence.createTransaction()) {
// get EntityManager for the current transaction
EntityManager em = persistence.getEntityManager();
// create and execute Query
Query query = em.createQuery(
"select sum(o.amount) from sample_Order o where o.customer.id = :customerId");
query.setParameter("customerId", customerId);
result = (BigDecimal) query.getFirstResult();
// commit transaction
tx.commit();
}
Guideline 5-1 / INPUT-1: Validate inputs
Input from untrusted sources must be validated before use. Maliciously crafted inputs may cause problems, whether coming through method arguments or external streams. Some of the examples are overflow of integer values and directory traversal attacks by including "../" sequences in filenames. In CUBA, you can use validators in the GUI in addition to checks in your code.
Those above are just a few examples of secure coding principles. Please read the guide carefully, it will help you to improve your code in many ways.
Keep Personal Data Secured
Some personal information should be protected because it is a law requirement. In Europe we have GDPR, for the medical application in the USA, there are HIPAA requirements, etc. So, take it into consideration when implementing your application.
CUBA allows you to set various permissions and restrict access to data using roles and access groups. In the latter, you can define various constraints that will allow you to prevent unauthorized access to personal data.
But providing access is only one part of keeping personal data secured. There are a lot of requirements in data protection standards and industry-specific requirements. Please have a look at these documents before planning the application’s architecture and data model.
Alter or Disable Default Users and Roles
When you create an application using CUBA framework, two users are created in the system: admin and anonymous. Always change their default passwords in the production environment before the application is available to users. You can do it either manually or add an SQL statement to the 30-....sql initialization script.
Use recommendations from the CUBA documentation that will help you to configure roles properly in production.
If you have a complex organizational structure, consider creating local administrators for each branch instead of several “super-admin” users at the organization level.
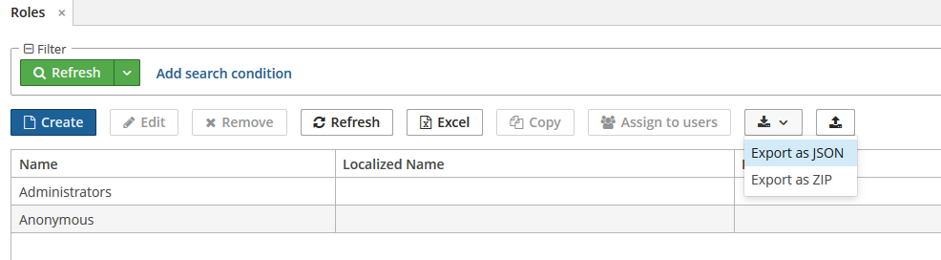
Export Roles to Production
Before the first deploy, you usually need to copy roles and access groups from your development (or staging) server to the production one. In CUBA, you can do it using a built-in administrative UI instead of doing it manually.
To export roles and privileges you can use Administration -> Roles screen. After the file is downloaded, you can upload it to the production version of the application.
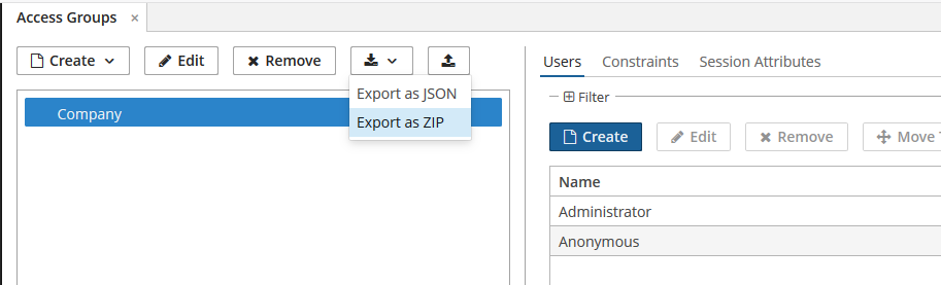
For Access Groups there is a similar process, but you need to use Administration -> Access Groups screen for this.
Configuring Application
The production environment is usually different from the development one, as well as application configuration. It means that you need to perform some additional checks to ensure that your application will be running smoothly when it comes to prod.
Configure Logging
Ensure that you configured the logging subsystem properly for production: log level is set to the desired level (usually it is INFO) and logs won’t be erased at the application restart. You can refer to the documentation for the proper log set up and useful loggers reference.
If you use Docker, use Docker volumes to store log files outside the container.
For the proper logging analytics, you can deploy a special facility to collect, store and analyze logs. Examples are ELK stack and Graylog. It is recommended to install logging software to a separate server to avoid a performance impact on the application.
Running in Clustered Configuration
CUBA applications can be configured to run in a cluster configuration. If you decide to use this, you need to pay attention to your application architecture, otherwise, you may get unexpected behavior from your application. We’d like to draw your attention to the most used features that you need to tune specifically for the cluster environment:
Task scheduling
If you want to execute a scheduled task (or tasks) in your application like daily report generation or weekly email sending, you can use the corresponding framework built-in feature. But imagine yourself as a customer that got three identical marketing emails. Are you happy? This may happen if your task is executed on three cluster nodes. To avoid this, prefer the CUBA task scheduler that allows you to create singleton tasks.
Distributed Cache
Caching is the thing that may improve application performance. And sometimes developers try to cache almost everything because memory is pretty cheap now. But when your application is deployed on several servers, the cache is distributed between servers and should be synchronized. Synchronization process happens over a relatively slow network connection and this may increase response time. The advice here - execute load tests and measure performance before making a decision about adding more caches, especially in a clustered environment.
Conclusion
CUBA Platform simplifies development, and you probably finish development and start thinking about going to production earlier than you expected. But deploy is not a simple task, whether you use CUBA or not. And if you start thinking about the deploy process on the early development stage and follow simple rules stated in this article, there is a good chance that your way to production will be smooth, requiring minimal efforts, and you will not face serious issues.